An artifical neural network spam classifier
Project home page: www.interstice.com/drewes/cs676/spam-nn
Rich Drewes
drewes at interstice.com
CS676, Prof. Sushil Louis
5/8/2002
Abstract
An artificial neural network (ANN) is implemented to classify emails into “spam” and “real” messages based on simple textual analysis of the emails. The recognition capability of the ANN is found to be good, but because of a low but nonzero false spam recognition rate (real messages erroneously classified as spam), the ANN is not suitable for use alone as a spam rejection tool.
1.0 Background
The author made the mistake ten years ago of using his main email address in a domain registration and in numerous USENET news posts. Today, more than 85% of all email received at his email address is “spam.” Spam is the common term for unsolicited commercial email (UCE). More generally, the word spam is sometimes used to describe undesired non-personal email of most any sort, even if it is not specifically commercial. This broader definition would include things like viruses, even when forwarded unwittingly from known correspondents.
Many techniques currently exist for attempting to identify incoming email as spam, and numerous tools exist using these techniques to attempt to sort email as it arrives at the user's mailbox or mail client program. Two representative examples of end-user spam classifiers are the NAGS Spam Filter (www.nags.org/) and SpamBouncer (www.spambouncer.org/). These mailbox spam classification tools are often Perl scripts used in conjunction with procmail filters using numerous heuristics to attempt to classify email. Some modern email client programs also include customizable spam classification heuristics.
Some of the common classification heuristics employed involve:
Identifying sending domains from which spam is known to originate
Identifying email from relay hosts known to forward spam
Identifying email from unknown or strangely formatted senders, or senders in certain domains (e.g. moneyman32432432@hotmail.com)
Identifying keywords common to much spam (e.g. “make money fast” or “multi level marketing”), or using other simple textual analysis such as looking for odd spacing or LOTS OF CAPITAL LETTERS or exclamation points!!!!
Identifying common spam mass-mailer programs based on mail headers, or defects in these mass-mailer programs' attempts to masquerade as conventional mailers
Identifying email received in foreign character sets (e.g. Chinese “Big 5” for English mailboxes)
Identifying incorrect or inconsistent information in the “received” history in the mail headers, or in other mail headers, for example mail purporting to be from a domain that does not agree with the IP address from which the mail was actually received
Sometimes strategies for blocking spam are implemented at the mail server daemon level rather than at the mailbox level. Some popular techniques here involve “boycott lists” like the Distributed Spam Boycott List (www.dsbl.org) in which many users all over the world contribute the names of known open and exploitable relay hosts or known spam origins. Spammers constantly search the Internet for “open relays” which are simply machines on the Internet running mail servers that naively accept for delivery emails addressed to third parties. Such open relays used to be the norm on the Internet. Nowadays, however, such hosts are used by spammers to hide their tracks and postpone complaints to their own Internet service providers, which will almost certainly shut down the spammers' accounts as soon as they become aware of the situation. By blocking mail from these hosts, from which little or no legitimate email originates, receipt of spam is also blocked.
The author has recently implemented a similar technique he has called Spamslam. It works like this: a number of artificial spam “trap” addresses are created and seeded to the Internet where, over time, they are gathered by spammers and included in spam mailing lists. These email addresses should never receive legitimate email since they are not actual addresses used by anyone. So, when mail is received by any spam trap address, the IP address of the host from which the mail was received is immediately placed in a block list, and the mail server never again will permit email from that IP address. This has been installed on the author's small ISP mail server (about 15,000 emails a week) and the system already rejects about 5% of all incoming mails as spam. The efficacy is increasing with use, as more and more open relays are included in the list.
The consequences of misclassifying a real message as a spam message (false positive spam identification) are much greater than misclassifying a spam message as real (false negative classification). In fact, some would say that any nonzero false positive spam detection rate are unacceptable, since that rejected email could be a job offer, grad school acceptance email, and so on. As email becomes used more and more for important functions, this danger becomes ever more real. Consequently, many spam classifiers remove emails classified as spam from the general mail flow but preserve them in a holding area for review before deletion. This prevents incoming spams from constantly disrupting a person's work flow, and confines the final pre-deletion check to (perhaps) a once-a-week quick review of From: and Subject: lines for all the collected spams for the week.
2.0 Design
This project describes an ANN (artificial neural net) based implementation of a spam classifier. Perhaps the most critical design consideration was the selection of inputs for the ANN. The literature on neural net based spam detection is not long, but a few techniques have been described. Androutsopoulos et. al., 2000 have described systems based on general document classification similar to those used by Sahami et. al., 1998. This technique was found to be fairly successful but insufficient alone. It is interesting that a stylistic analysis tool can be used to identify spam. This agrees with this author's perception that the text content of most spam is borderline illiterate.
This project investigated several variants of a simpler approach. The basic idea used in this project is to create a word list w of the n most frequently used words in certain parts (initially just the message body) of the training corpus of spam and real messages. The elements in of the ANN input vector i for a given message are then derived as follows. If the email in question contains mn instances of the word in the nth position of the global wordlist, and if the email in question has l words, then in will be set to mn/l. The input vector is thus simply a representation of the presence or absence of the words in the global word list, weighted by the length of the message itself.
A “word” in the above context is defined as any series of upper or lower case alpha characters greater than three characters and less than 15 characters in length. When the words are placed into the wordlist, they are converted to all lower case, and all comparisons done against the wordlist are subsequently done in lower case.
In this scheme, no consideration of the proximity of certain word combinations is made. For example, the word “make” occurring close to “money” occurring close to “fast” would be a strong indication that the email is a spam, but the technique would not pick up on the fact that they occurred close together.
These inputs were fed into a simple three-layer (input, hidden, and output) fully connected conventional artificial neural network. The network was trained for a certain number of training epochs for every input in the training set, with the weights adjusted using backpropagation. The ANN used in this project was the same CMU derived code used in the face recognition project.
3.0 Experiment
A number of parameters were varied in different experimental runs, including:
The size of the wordlist was tried with either the 1000, 2000, 3000, or 4000 most frequent words in the training set corpus. The wordlist size corresponds to the size of the ANN input vector. 1000 was found to result in significantly lower performance, but little difference was found in sizes of 2000 and above
The number of nodes in the hidden layer. This was varied from two to 24. Surprisingly, a hidden layer size of two nodes worked very nearly as well as four but showed somewhat lower performance on the validate and test sets, so four was used in most experiments. Very large number of nodes in the hidden layer did not increase performance.
Whether the number-of-words “weight” factor was defined as the total number of words found in the email, or the number of matched words in the email (i.e. words present in the global wordlist). The ANN classified significantly better if l was the number of matched words. The inputs were also tried as totally unweighted; this resulted in the ANN never performing much better than chance.
Whether the word list and input vector was made up of words in the body of the email only, or the body plus the Subject: header. The ANN classified better if the Subject: header was included.
A manually classified corpus of 1592 real and 1730 spam emails received by the author over a period of several months was randomly split into three mixed groups: a training set (n=2043), a validation set (n=631), and a test set (n=649).
4.0 Results
The ANN achieved high recognition accuracy. The highest classification accuracy observed was with a hidden layer of four nodes, a wordlist size of 2000 words, the wordlist coming from email body and Subject: header, and the weight divisor being the total number of matched words. The results were as shown in table 1.
|
Training Epoch |
Training Set |
Validation Set |
Test Set |
|---|---|---|---|
|
100 |
97.36% |
93.82% |
93.99% |
|
200 |
99.71% |
97.31% |
97.53% |
|
300 |
99.90% |
98.26% |
98.00% |
Table 1
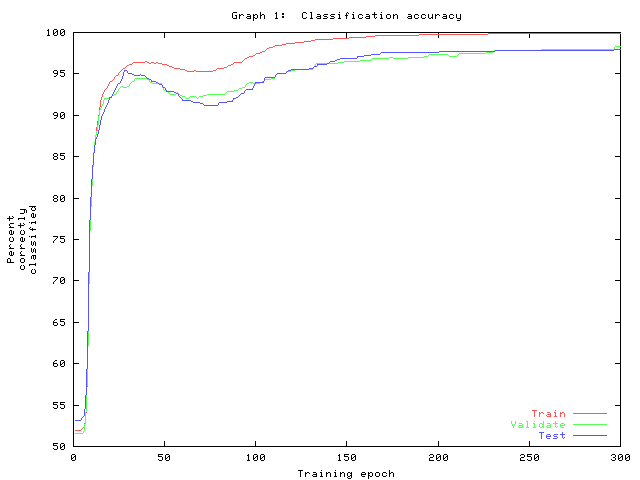
Graph 1 shows the time course of accuracy of the three data sets. The overshoot near epoch 50 suggests the training parameter is somewhat high.
An investigation of classification errors is interesting and instructive. Of the 26 misclassified emails in all data sets after epoch 300 for the above run, 9 were false negatives (spam erroneously classified as real email) and 17 were more serious false positives (real email erroneously classified as spam).
In most cases, the false negative errors were understandable when the email in question was examined. The false negative errors were roughly as follows:
A spam with no body text. This resulted in insufficient information to classify.
A spam with a chatty slang-filled and short text body with a Javascript attachment
A spam in German, which therefore resulted in few wordlist matches
A spam containing a Chinese political newsletter (in a Chinese character set) with a brief introductory English text
A spam with a short, chatty text body and a URL pointing to “Brit girls getting their kit off” that actually looked sort of interesting
A spam with no text in the body, just a Javascript program
A spam with a variant of the Nigerian banking scam. This contained significant and diverse text, but the text is unusually sophisticated for a spam.
A foreign language spam, with an attachment
Another foreign language spam, with an attachment
The false positive errors were roughly as follows:
Three emails from a known correspondent whose emails are, frankly, subjectively spam-like and often not worth reading. These emails were MIME encoded and contained a business card binary attachment.
An advertisement from a known correspondent that wasn't solicited, but nevertheless was desired. This arguably could not be detected using the techniques described here.
A rental confirmation from Dollar Rent-a-Car which shared a number of spam-like characteristics
An “evite” email initiated by a known correspondent but coming from the Evite organization and containing an advertisement at the end
A letter from a known correspondent to an email list to which the author subscribes apologizing for bounced emails
An advertisement from a company from which the author had downloaded a free trial. This email looked very much like spam and arguably couldn't be detected using the techniques described here.
A question from a known correspondent concerning his email account on my server
A legitimate subscription confirmation from an email list the author joined
A letter from a UNR professor (not in the CS department) that was MIME encoded and contained a large binary attachment
An email from an ISP concerning billing
An email from a legitimate mailing list that happened to contain an advertisement
An email from a known correspondent that contained a forwarded humorous yet semi-threatening email
An email from a known correspondent concerning a spam filter installed on one of the author's servers
A letter from a legitimate email list to which the author subscribes that contained no text body, just a base64 encoded attachment
A letter from a known correspondent containing an informal “advertisement” for a dinner-and-a-movie gathering
It is interesting to note that the content topic of several of the false positives emails was the subject of email itself.
5.0 Conclusions
The ANN spam classification techniques described here proved to be useful and accurate. However, its false positive classification rate of about 1% is too high for unsupervised use. Two adjunct strategies could be used to supplement the base ANN classifier and enable it to be used in a real production environment:
A “known correspondents” list which would guarantee unblocked receipt of all email from people whom the user had identified as a valid sender. The user would update this list from time to time, adding new mailing lists or individual senders as they arose.
A manual review of emails classified as spam prior to deletion. This is not as onerous as it sounds; a quick weekly review of From: and Subject: headers will allow the user to catch the very small percentage of real messages misclassified as spam.
It would be interesting to repeat the experiment with the test emails used in Androutsopoulos, et. al. 2000. It is my suspicion that my own test data presented a considerably more difficult problem than the emails in the other paper's test data.
Finally, it is not known how much the performance of the static wordlist approach described here would degrade classification over time. The results presented here might be artificially high because the wordlist was compiled from spam and real messages that sample the entire timespan of all messages in all data sets (training, validation, and test). As trends in spamming change over time, and as topics of conversation in a user's real emails vary over time, we might expect fewer words from future emails to match the wordlist, and consequently discrimination capability for the spam ANN might decline.
6.0 References
Sahami, M., Dumais, S., Heckerman, D., and Horvitz, E. A Bayesian Approach to Filtering Junk E-Mail. In Learning for Text Categorization—Papers from the AAAI Workshop, pp. 55-62, Madison Wisconsin. AAAI Technical Report WS-98-05, 1998.
Androutsopoulos, I., Koutsias, J., Chandrinos, K., Paliouras, G., Spyropoulos, C. An Evaluation of naïve Bayesian Anti-Spam Filtering. In Proceedings of the workshop on Machine Learning in the New Information Age, 11th European Conference on Machine Learning, pp 9-17, Barcelona, Spain, 2000.
7.0 Acknowledgments
The tools used in the creation of this program and document were entirely open source and include: Linux, vim, GNU utilities (bash, sort, uniq, grep...), gcc, gnuplot, OpenOffice, Mozilla, ImageMagick 'display', X11R6, and CMU simple backprop NN. The program and document were created in a completely Microsoft free environment.