Sunday, September 27, 2015
Furf2 on Mnist
[Research Log]
I tried the method outlined here and here on Mnist. It works reasonably well, but not spectacularly enough to get excited about. Here's a quick summary of the results:
For starters, here's a random sample of the mnist training set (this is what we are tasked to learn):

With two hidden layers, 49 16-state units feeding to 16 49-state units, the unsupervised net models the data like this after just a little training:
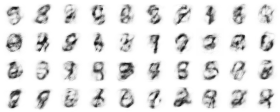
and after a lot of training:
Notice that it's trying to make number-like things, but isn't too concerned with keeping the categories distinct. (There's no contextual information here to tell it what's important.)
If we add a single 10-state node on top of that and force its state to the training label, which somewhat emulates contextual feedback, we get this after a little training:

And eventually this:

Incidentally, without (a slightly modified) SMORMS3 it's much slower and starts out like this:

I modified SMORMS3 to a vector form that scales at the input group level rather than individual weights, in order to preserve the auto-normalization of this particular learning rule. Otherwise it's the same.
The state of the top-level 10-state node after the upward evaluation pass can be used as a classifier. Doing that yields about 3.45% error rate on the mnist testing set (with no preprocessing or training set enhancement), which puts it in the ballpark of some of the older Neural Net results. To be fair, forcing a top level node to a target state isn't really the correct way to "supervise" this kind of network, but it was a quick hack to implement so that's what I did. I'm more interested in the unsupervised behavior.
Remember, this is all done with a very simple evaluation rule and an even simpler learning rule, with no auto-differentiation or whatnot required. (I implemented the above in vanilla C. The lack of an integer-result multinomial sampler in numpy, theano, and the like is problematic...)
My sense is it's cute, but I think restricting the downward convergence rule to a product of distributions is too limiting. I might play with Variational Bayes next (which is more closely related to the above than it first appears...).